فایل robots.txt چیست؟
فایل robots.txt را مثل یک تابلوی کوچک «منشور رفتاری» در نظر بگیرید که روی دیوار یک باشگاه ورزشی یا اتاق مدیرعامل شرکت نصب شده است. این تابلو به خودیخود قدرتی برای اجرای قوانین ذکرشده ندارد؛ اما قوانین را برای ورزشکاران یا کارمندان مشخص میکند. علاوهبراین، هر زمان مشکلی در رفتار افراد یک محل پیش بیاید، میتوانیم به این تابلو رجوع کنیم و نکات مهم را یاداور شویم. همچنین میتوانیم در صورت تغییر قوانین رفتاری، متن این تابلو را عوض کنیم.فایل robots.txt دقیقا این تابلو است. یک فایل متنی کاملا سادهای که دستورات آن متنی هستند و رفتار خزندههای موتورهای جستوجو را در سایت ما مشخص میکنند.در واقع، همانطور که میتوان قوانین تابلوی رفتاری را بهروزرسانی کرد، تنظیم دقیق و درست فایل robots.txt نیز بخشی از مدیریت فنی سایت است. برای اینکه این تنظیمات به درستی عمل کنند، لازم است ساختار دامنه و هاست شما نیز بهدرستی پیکربندی شده باشد. به همین دلیل، آموزش اتصال دامنه به هاست در سی پنل میتواند نقش مهمی در درک بهتر نحوه ارتباط بین فایلهای سایت و دسترسی خزندههای موتورهای جستوجو ایفا کند.
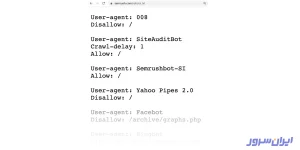
مثلا به خزندهها میگویند که به صفحه آرشیو (Archive) سایتمان سر نزنند. در عوض باید حواسشان به صفحه اصلی سایتمان باشد و همیشه آن را بررسی کنند.
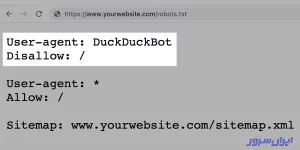
همچنین میتوانیم دسترسی خزندههای یک موتور جستوجو را ببندیم و به موتورهای دیگر اجازه کراول بدهیم. تصویر زیر نمونهای از این حالت است که دسترسی موتور جستوجوی DuckDuckGo را میبندد؛ اما به همه موتورهای دیگر اجازه خزش میدهد.
چرا باید از فایل robots.txt برای سایت خود استفاده کنیم؟
اگر از فایل robots.txt استفاده نکنیم، رباتهای تمام موتورهای جستوجو به سایتمان میرسند و تمام صفحات را پیمایش میکنند.
خب این موضوع دو مشکل اساسی بهوجود میآورد:
۱. اول اینکه هر موتور جستوجو، زمان مشخصی برای خزش یا ‘Crawl’ در نظر گرفته است که به آن بودجه خزش یا ‘Crawl Budget’ میگوید. این خزندهها نمیدانند که کدامیک از صفحات سایتمان مهم هستند و کدام صفحات اهمیتی ندارند. بنابراین ممکن است فقط به صفحات غیرمهم سر بزنند و دیگر بودجهای برای خزش صفحات مهم نماند.
۲. اگر فایل robots.txt نداشته باشیم، خزندههای هر موتور جستوجو به سایتمان سر میزنند و ترافیک سنگینی بهوجود میآورند. چون این رباتها برای هاست ما، دقیقا مثل درخواست کاربران هستند. بنابراین بار پردازشی سنگینی به هاست تحمیل شده و ممکن است از دسترس خارج شود یا افت سرعت شدیدی را تجربه کند. در نتیجه سایتمان از دسترس کاربران خارج میشود و کسبوکارمان برای چند ساعت تعطیل خواهد شد.
تفاوت فایل robots.txt با Meta Robots و x-robots
ما با فعالیت در اینترنت و طراحی سایت، میخواهیم دیده شویم و خدمات یا محصولاتمان را به تمام مخاطبان مدنظرمان معرفی کنیم. وقتی بهسمت طراحی سایت با وردپرس یا هر پلتفرم دیگری میرویم، این سه فایل به چشممان میخورد. بنابراین در ادامه، مقایسهای بین هر سه خواهیم داشت.
فایلهای robots.txt، Meta Robots و x-robots همگی موتورهای جستجو را در مورد نحوه مدیریت محتوای سایت شما راهنمایی میکنند.
اما آنها در چند جنبه تفاوتهایی با یکدیگر دارند که میتوان از مهمترین آنها به سطح کنترل، محل ذخیرهسازی هر کدام و آنچه که کنترل میکنند، اشاره کرد. در ادامه، بهشکل جزئیتر به تفاوتهای هر کدام از این سه فایل میپردازیم.
- robots.txt: این فایل در دایرکتوری root وبسایت شما قرار دارد و درست مثل یک دروازهبان عمل میکند. مسئولیت اصلی این فایل این است که دستورالعملهای کلی و سطحی سایتتان را به خزندههای موتورهای جستوجو ارائه دهد. یعنی به آنها بگوید که باید در چه مناطقی از سایت شما بخزند و به کجاها اصلا رجوع نکنند.
- Meta Robots: این فایل قطعههایی از کد است که در بخش <head> صفحات وب قرار دارد. فایل Meta Robots دستورالعملهای خاص صفحات را در مورد فهرست کردن (یا همان Index کردن، بهمعنی نمایش در نتایج جستوجو) و دنبال کردن (خزیدن رباتها بین پیوندهای داخلی سایت) هر صفحه به موتورهای جستوجو دیکته میکند.
- x-robots: این فایل، قطعههای کدی است که عمدتا برای فایلهای غیر HTML، مثل PDF و تصاویر استفاده میشود. محل ذخیرهسازی x-robots، هدر HTTP فایل است.
فایل robots.txt کجای سایت ما است؟
فایل robots.txt در root دامنه سایتتان است و باید همیشه آنجا بماند. پس اگر دامنه شما www.example.com است، این فایل باید در مسیر https://www.example.com/robots.txt باشد.
نکته دیگر درباره قرارگیری این فایل، نامش است. حتما باید فایل با همین نام، یعنی robots.txt ساخته و ذخیره شود. این نام به حروف کوچک و بزرگ حساس است و تمام حروفش بهشکل حرفهای کوچک انگلیسی نوشته میشوند.
۵ دستور بسیار مهم در فایل Robots.txt
فایل robots.txt از یک یا چند بلوک دستورالعمل تشکیل شده است که خط ‘user-agent’، رفتار یک موتور جستوجوی خاص را مشخص میکند. نمونه دستور آن بهشکل زیر است:
User-agent: Googlebot Disallow: User-agent: bingbot Disallow: /not-for-bing/
اگر میخواهید رفتار خزندههای تمام موتورهای جستوجو در سایت شما یکسان باشد، از یک علامت ستاره برای این دستور استفاده کنید. به عبارتی دیگر، با علامت * قوانین را به خزندههای تمام موتورهای جستوجو دیکته میکنید. نمونه کد زیر، مثال واقعی بهکار بردن این علامت است:
User-agent: * Disallow: /
جزئیات هرکدام از این دستورها را در ادامه خواهید خواند.
- دستورالعملهایی مانند Allow و Disallow که زیر user-agent میآیند، به حروف بزرگ و کوچک حساس نیستند.
- مقادیر این دستورها به حروف کوچک و بزرگ حساس هستند. مثلا /photo/ با /Photo/ متفاوت است.
۱. user-agent
اکثر موتورهای جستوجو چند خزنده برای بخشهای مختلفشان دارند. مثلا وقتی چیزی را در گوگل سرچ میکنید، در قسمت بالا، چند تب میبینید: ‘News’، ‘Images،’ Books’ و غیره.
وقتی خزندهها به فایل robots.txt سر میزنند، دستورالعمل مربوط به هر بخش را دنبال میکنند.
فرض کنید سه مجموعه دستورالعمل دارید: یکی برای همه خزندهها که با علامت * مشخص شده است، یکی دیگر برای Googlebot و دیگری برای Googlebot-News.
اگر خزندهای توسط user-agent به بخش Googlebot-Video وارد شود، از محدودیتهای Googlebot پیروی میکند. یک ربات با user-agent بخش Googlebot-News هم از دستورالعملهای Googlebot-News استفاده میکند.
۲. Disallow
خط دوم در هر بلوک دستورالعمل، خط Disallow است. شما میتوانید یک یا چند مورد از این خطوط را داشته باشید و مشخص کنید که خزنده مشخصشده، به کدام بخش از سایتتان نباید دسترسی داشته باشد.
یک خط Disallow خالی به این معنی است که شما دسترسی را برای خزش همه چیز باز نگه داشتهاید تا ربات موتور جستوجو بتواند به تمام بخشهای سایتتان دسترسی داشته باشد.
مثلا دستور زیر، دسترسی تمام موتورهای جستوجو را به سایتتان مسدود میکند و به خزندهها میگوید که به کل سایت دسترسی ندارند:
User-agent: * Disallow: /
اگر کاراکتر / را در کد قبل بردارید، در واقع به همه موتورهای جستوجو اجازه دادهاید که در سایت شما بخزند و همه چیز را بررسی کنند. نوشتن دستور زیر چنین کاری را انجام میدهد:
User-agent: * Disallow:
مثال زیر، گوگل را از خزیدن در دایرکتوری عکسها در سایت شما و هر چیزی که در این دایرکتوری قرار دارد، منع میکند و دسترسی نمیدهد.
User-agent: googlebot Disallow: /Photo
این بدان معنی است که تمام زیر شاخههای دایرکتوری /Photo توسط خزندههای گوگل دیده نمیشوند و اجازه دسترسی ندارند.
مجدد یاداوری میکنیم که مقدارهای روبهروی این دستورالعملها، به حروف بزرگ و کوچک حساس هستند. پس گوگل از خزیدن در دایرکتوری /photo منع نمیشود؛ چون ما این کلمه را با حرف P بزرگ نوشتیم.
۳. Allow
اگر در دایرکتوری Photo، یک پوشه با نام Photography داشته باشید، خزندههای گوگل حق دسترسی و خواندن آن را نخواهند داشت؛ چون یک زیر دایرکتوری از دایرکتوری Photo است.
گوگل درک بیشتری از فایل robots.txt دارد. بههمیندلیل، این موتور دستور Allow را متوجه میشود؛ درحالیکه موتورهای جستوجوی دیگر، هنوز به درک آن نرسیدهاند.
اگر میخواهید به خزندههای گوگل بگویید که یک صفحه را کراول کند، باید بهجای Disallow، از Allow استفاده کنید.
مثلا ما در همان دایرکتوری Photo، یک عکس با نام ‘cent.jpg’ داریم. میخواهیم دسترسی به دایرکتوری Photo را مسدود نگه داریم و به خزنده گوگل بگوییم فقط همین عکس را کراول کند. پس دستور زیر را مینویسیم:
User-agent: googlebot Disallow: /Photo Allow: /Photo/cent.jpg
۴. XML Sitemap
فایل sitemap تمام منوها، زیر منوها، صفحات و سلسله مراتب صفحات را مشخص میکند که کدهای آن چیزی شبیه تصویر زیر است:
این تصویر برای انسانها قابل درک است؛ اما کامپیوتر، رباتها و خزندههای موتورهای جستوجو، هیچ درکی از آن ندارند. پس باید آن را به کدهای XML تبدیل و با نام sitemap.xml، در مسیر root هاست ذخیره کنیم. این فایل حاوی کدهای HTML است که تصویر زیر، یک نمونه کوچکی از آن را نشان میدهد:
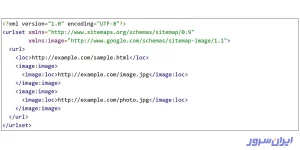
با استفاده از دستورالعمل sitemap، میتوانید به موتورهای جستوجو مثل یاندکس، بینگ و گوگل بگویید که نقشه سایت XML شما را در کدام مسیر پیدا کنند. البته، میتوانید نقشههای XML سایتتان را با استفاده از ابزارهای وبمستر هر موتور جستوجو بسازید و برای خزندهها بهشکل مستقیم بفرستید.
ما توصیه میکنیم که این کار را بهشکل مستقیم انجام دهید؛ چون ابزارهای وبمستر اطلاعات زیادی در مورد سایت شما دارند که در اختیار خودتان قرار دارند و میتوانید robots.txt را با دقت و ظرافت بیشتری بسازید.
اگر فعلا نمیخواهید این کار را انجام دهید، باید یک خط sitemap به فایل robots.txt اضافه کنید. یکی از معروفترین افزونه های وردپرس، یعنی Yoast SEO، این کار را بهطور خودکار انجام میدهد و یک لینک به نقشه سایت شما اضافه میکند. البته قبل از این کار، باید به آن اجازه دهید که فایل robots.txt را خودش بسازد.
اگر ترجیح میدهید که خط sitemap را بهشکل دستی در فایل robots.txt بگذارید، دستور زیر را کپی کنید:
Sitemap: https://www.example.com/my-sitemap.
۵. Crawl-Delay
این فرمان به موتور جستوجو میگوید که خزندههایش باید صبر کنند و با یک مقدار تاخیر بین دو خزش، کارشان را انجام دهند. مثلا اگر مقدار Crawl-Delay را ۸ بگذاریم، خزندهها ۸ میلی ثانیه صبر میکنند و صفحه A را خزش میکنند. سپس ۸ میلی ثانیه دیگر هم منتظر میمانند و صفحه B را میخزند.
اگر سایت یا فروشگاه اینترنتیای دارید که روی هاست وردپرس یا هاست ووکامرس مستقر است و صفحات خیلی زیادی دارد، استفاده از این دستورالعمل کمک زیادی به کاهش بار ترافیکی و پردازشی هاستتان میکند.
استفاده از فرمان Crawl-Delay یک نکته ریز دارد؛ آن هم این است که گوگل این فرمان را نمیشناسد؛ اما موتورهای جستوجوی دیگر آن را تشخیص میدهند و میفهمند. اگر میخواهید از این دستور در فایل robots.txt خودتان استفاده کنید و خزندههای گوگل را هدف بگیرید، باید آن را در سرچ کنسول تنظیم کنید.
نحوه کار فایل robots.txt چگونه است؟
اگر به یک سایت مراجعه کنید، چند منو، گزینه و دکمه میبینید. هرکدام از این آیتمها، شما را به صفحه دقیقی هدایت میکند که محتوای خاص خود را دارد. مثلا همین الان، شما در صفحه «فایل robots.txt چیست و چرا برای سئو سایت خیلی مهم است؟». این صفحه چند لینک به محتوای دیگر و محصولات ایران سرور دارد. از طرفی دیگر، تمام صفحات مقالات ایران سرور، در زیردامنه blog.iranserver.com ذخیره میشوند.
طرز کار فایل robots.txt به این شکل است که با دستورالعملهای خود، مشخص میکند که خزندههای گوگل به این صفحه بیایند و به تمام لینکهای داخلی آن سر بزنند. چون این خزندهها مثل انسان هستند و تمام محتوای یک صفحه سایت را میبینند؛ اما زبانشان کامپیوتری است و با دستورالعملهای موجود در فایل robots.txt محتوا را میخوانند و میفهمند؛ نه با کلمات یا تصاویر بصری.
با خزیدن در صفحات وب، این رباتها لینکها را کشف و دنبال میکنند. اگر ما از ایران سرور به سایت Yoast لینک بدهیم، این خزندهها از سایت ما – مثلا سایت A – به سایت Yoast – همان سایت B – میرسند. همینطور ممکن است در سایت A، به چند لینک داخلی برسند و محتوای آنها را بررسی کنند.
وقتی رباتها به سایتی سر میزنند، قبل از هر چیزی بهدنبال فایل robots.txt میگردند تا بدانند اجازه دسترسی به کدام صفحات را دارند.
درحالیکه یک فایل robots.txt حاوی دستورالعملهایی برای رباتها است، اما نمیتواند دستورالعملهای خودش را اجرا کند.
نکته مهمی که باید به آن توجه داشت این است که همه ساب دامین یا زیردامنهها، به فایل robots.txt خود نیاز دارند. مثلا دامنه اصلی ایران سرور آدرس ‘iranserver.com’ است. بلاگ آن در ساب دامین blog.iranserver.com قرار دارد. پس یک فایل robots.txt را برای دامنه اصلی و یک فایل robots.txt دیگر را برای زیردامنه بلاگ ایران سرور میسازیم.
چرا robots.txt برای سئو سایت مهم است؟
یک فایل robots.txt به مدیریت فعالیتهای خزندههای اینترنت کمک میکند. بنابراین وبسایت شما مجبور نیست بیشازحد کار کند یا مجبور باشد صفحاتی را قایم کند که بهشکل خصوصی در سایتتان نگه میدارید. اما دلایل اهمیت فایل robots.txt برای سئو سایت کمی فراتر از این موضوع است که در ادامه توضیح خواهیم داد.
۱. بهینهسازی بودجه خزش
بودجه خزیدن به تعداد صفحاتی اشاره دارد که گوگل میتواند در یک بازه زمانی معین و محدود، از سایت شما ببیند. این تعداد میتواند بر اساس اندازه، سلامت و تعداد بکلینکهای سایتتان متفاوت و متغیر باشد.
اگر تعداد صفحات سایت شما از بودجه خزش بیشتر باشد، ممکن است صفحات مهمی ایندکس نشوند. اگر صفحهای خزش نشود، رتبهای هم نمیگیرد. این یعنی وقتتان را هدر دادهاید؛ چون کاربر اصلا آن صفحات را نمیبیند.
بنابراین از فایل robots.txt استفاده میکنیم تا خزش صفحات غیرضروری را مسدود کنیم و از بودجه خزشمان برای صفحات مهم بهره ببریم.
۲. حذف صفحات تکراری و خصوصی از نتایج جستوجو
رباتهای خزنده نیازی به بررسی هر صفحه در سایت شما ندارند؛ چون همه آنها ارزشی برای کاربر ندارد و برخی دیگر را اصلا برای ارائه در نتایج موتورهای جستوجو ایجاد نکردهاید. مثلا صفحه Search سایتها که در داخل سایت جستوجو کالا یا مقاله را انجام میدهد، صفحات تکراری یا صفحات لاگین کاربران. برخی از انواع سیستم مدیریت محتوا این صفحات داخلی را بدون دخالت شما و بهشکل بهینهای مدیریت میکنند.
بهعنوان مثال، وردپرس بهطور خودکار صفحه ورود به سیستم که با نام “/wp-admin/” است را برای همه خزندهها مسدود میکند.
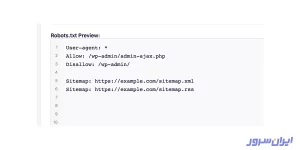
۳. مخفی کردن منابع
گاهی اوقات، در سایتمان یکسری منابع و محتوای آموزشی گذاشتهایم که نمیخواهیم در صفحات نتایج دیده شوند. مثلا فایلهای PDF، راهنماهای ویدیویی، تصاویر آموزشی و غیره. علت این کار هم این است که میخواهیم این منابع خصوصی نگه داشته شوند و گوگل فقط روی محتوای مهمتر تمرکز کند.
فایل robots.txt اینجا به کمکمان میآید و از خزش رباتها در این بخشها جلوگیری میکند.
فایل robots.txt سایتمان را چطور پیدا کنیم؟
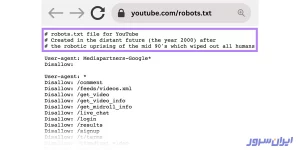
برای پیدا کردن فایل robots.txt باید به سیستم مدیریت محتوا و افزونههایمان مراجعه کنیم که چند راه مختلف دارد و در ادامه با آنها آشنا خواهید شد.
۱. مراجعه مستقیم به فایل
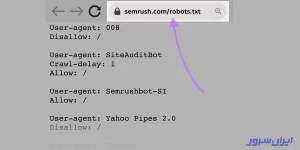
اولین و سادهترین کار این است که نام کامل دامنهتان را در نوار جستوجو مرورگرتان بنویسید، یک / بگذارید و robots.txt را بنویسید و دکمه Enter کیبورد را بزنید. مثلا وبسایت Semrush، فایل robots.txt را دقیقا بعد از نام کامل دامنهاش قرار داده که در تصویر زیر میبینید:
۲. کدهای بکاند سایت
اگر سایتتان بهصورت اختصاصی نوشته و طراحی شده است، باید آن را در کدهای Back-end جستوجو کنید.
۳. پیدا کردن فایل robots.txt با افزونههای وردپرس
پیدا کردن این فایل در سه افزونه وردپرس شامل Yoast، RankMath و All in One SEO بهشکل زیر است:
پیدا کردن فایل robots.txt با افزونه Yoast:
- وارد بخش wp-admin سایتتان شوید؛
- در نوار کناری، به افزونه Yoast SEO > Tools بروید؛
- روی گزینه ویرایشگر فایل یا ‘File editor’ کلیک و فایل را در آن جستوجو کنید.
پیدا کردن فایل robots.txt با افزونه RankMath:
- وارد بخش wp-admin خود شوید.
- در نوار کناری، به Rank Math > General Settings بروید.
- گزینه Edit robots.txt را پیدا و روی آن کلیک کنید تا محتوای فایل را ببینید.
پیدا کردن فایل robots.txt با افزونه All in One SEO:
- وارد بخش wp-admin خود شوید.
- در نوار کناری، به All in One SEO > Robots.txt بروید.
پیدا کردن فایل robots.txt در مجنتو نسخه ۲:
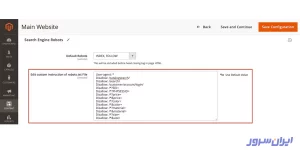
- مسیر Content > Configuration را بروید که زیر بخش Content قرار دارد.
- در این پنجره، میبینید که تنظیمات وبسایت اصلی، روی حالت Default Store View قرار دارد. آن را روی Main Website تنظیم کنید تا بتوانید فایل robots.txt را تغییر دهید.
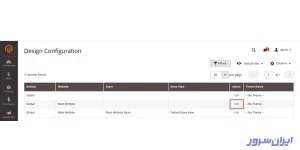
در صفحهای که باز میشود، اسکرول کنید تا به بخش Search Engine Robots برسید. حالا میتوانید محتوای robots.txt خود را تعریف کنید یا تغییر دهید.
نحوه ساخت فایل robots.txt
نحوه ساخت فایل robots.txt با دو حالت انجام میشود: ۱) با استفاده از کامپیوتر خودتان و ۲) توسط ابزارهای آنلاین.
۱. نحوه ساخت فایل robots.txt با کامپیوتر خودمان
اگر از CMSهایی مثل وردپرس یا جوملا استفاده نمیکنید یا CMSتان اجازه نمیدهد که فایل robots.txt بسازید، همیشه میتوانید خودتان یک فایل robots.txt بسازید و بهصورت دستی آن را در سرور یا هاستتان آپلود کنید.
برای انجام این کار، مراحل زیر را دنبال کنید:
- یک ویرایشگر مانند Notepad در ویندوز یا textEdit را در Mac OS X باز کنید.
- یک فایل جدید بسازید.
- یکی از نمونه فایلهای robots.txt را Copy-Paste کنید. میتوانید از کدهای همین مقاله یا جدول زیر استفاده کنید:
User-agent: Googlebot
Disallow: /nogooglebot/
User-agent: *
Allow: /
Sitemap: https://www.example.com/sitemap.xml
- محتویات را متناسب با نیاز خودتان بنویسید و تنظیم کنید.
- آن را با نام robots.txt روی کامپیوتر خود ذخیره کنید.
- بعد از اتمام این مراحل، به هاست سایتتان بروید و آن را در دایرکتوری root آپلود کنید.
۲. نحوه ساخت آنلاین فایل robots.txt
یکی از بهترین سایتهای ساخت فایل robots.txt، SEOptimer است که فقط باید پارامترها را تنظیم کنید و دکمه Create and Download Robots.txt آن را بزنید.
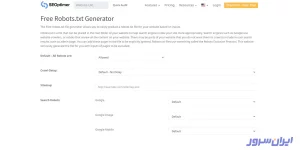
این سایت بهمحض ساخت فایل robots.txt شما، آن را در کادر که پایین صفحه قرار دارد، نشان میدهد.
اموزش مرحلهبهمرحله قرار دادن robots.txt در سرچ کنسول گوگل
برای قرار دادن robots.txt در سرچ کنسول گوگل، باید ابتدا فایل را در دایرکتوری root کنترلپنل سایتتان آپلود کنید.
برای انجام این کار، ما از سیپنل استفاده میکنیم؛ چون پراستفادهترین کنترلپنل است که با خرید سرور مجازی، کانفیگ VPS لینوکس و بسیاری از پلتفرمهای دیگر، همین کنترلپنل در اختیارتان قرار میگیرد.
۱. با نام کاربری و رمز عبور وارد سیپنل شوید و به بخش File Manager بروید.
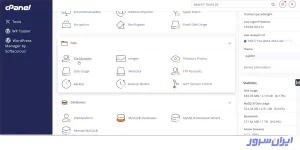
۲. پوشه public_html را از پنل سمت چپ انتخاب کنید.
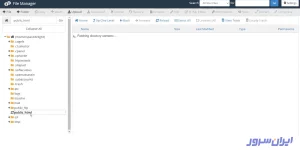
۳. برای آپلود فایل robots.txt در سیپنل، روی دکمه Upload بالای صفحه بزنید.
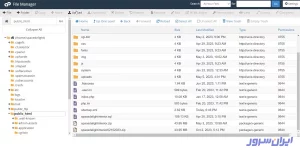
۴. در این پنجره، روی دکمه Select File کلیک و از سیستم خودتان، فایل robots.txt را انتخاب و آپلود کنید.
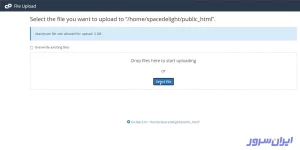
۵. وقتی نوار پیشرفت آپلود سبز شد و عدد ۱۰۰% را نشان داد، به این معنی است که فایلتان با موفقیت روی هاست آپلود شد.
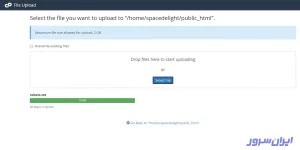
۶. نام کامل سایتتان را بنویسید و با یک /، robots.txt را به آن اضافه کنید. باید محتوای فایلتان را در صفحه، دقیقا مانند تصویر زیر ببینید:
۲
۷. به آدرس Support Google Webmaster بروید و روی دکمه Open robots.txt report کلیک کنید.
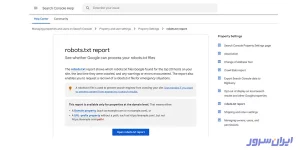
۸. در این پنجره، جزئیاتی درباره آخرین بازدید گوگل از آپلود فایل robots.txt را میبینید که پیغام OK روبهروی ساعت و تاریخ، نشان میدهد که خزندههای گوگل فایل شما را دیدهاند.
مراحل قرار دادن robots.txt در سرچ کنسول گوگل در همینجا به اتمام رسیده است؛ اما اگر میخواهید کار را با اطمینان خاطر بالا به اتمام برسانید، میتوانید در همین صفحه، روی دکمه Test قرمز رنگ، در پایین صفحه و سمت راست کلیک کنید.
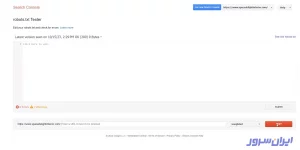
۹. اگر پیغام ALLOWED جایگزین کلمه Test شد، به این معنی است که آپلود فایل بهدرستی پیش رفته و برای گوگل خوانا و قابل درک است.
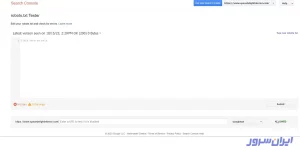
۱۰. حالا همین آدرسی که در نوار جستوجوی مرورگرتان میبینید را بهطور کامل کپی کنید و در یک تب جدید و خالی، Paste کنید.
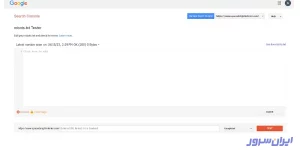
۱۱. از کادر Choose a verified property instead، لیست کشویی را باز و سایتتان را انتخاب کنید.
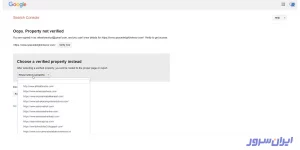
۱۲. صفحه زیر را پس از انتخاب فایل robots.txt در سرچ کنسول گوگل میبینید که حاوی محتوای آن است.
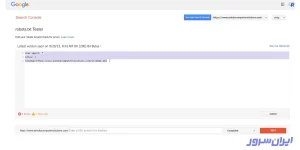
نکات مهم در کار با فایل robots.txt
چند نکته مهم در کار با فایل robots.txt اهمیت دارند که در ادامه، به آنها اشاره میکنیم. تمام این نکات، حین بهینه سازی فایل robots.txt برای سئو اهمیت دارند. بنابراین قبل از آپلود فایل robots.txt، مطمئن شوید که هر کدام از آیتمهای این بخش را تیک زدهاید.
۱-استفاده از ویرایشگر متن، نه واژهپردازها
Microsoft Word یک نرمافزار واژهپرداز است که وقتی فایل متنی را با آن مینویسید، فرمتهای خاصی را بدون اطلاع و آگاهی شما به آن اضافه میکند. فایل robots.txt حتما باید با برنامههای ویرایشگر متن نوشته شوند. در سرور مجازی لینوکس، این ویرایشگرها vi و emacs هستند. در لپتاپها و آیمکها، TextEdit و در ویندوز، Notepad است. هنگام ذخیره توسط هر کدام از این برنامهها، حتما فایل robots.txt را با سیستم Encoding UTF-8 ذخیره کنید.
۲-عدم مسدود کردن فایلهای CSS و JS در robots.txt
از سال ۲۰۱۵، سرچ کنسول گوگل به صاحبان سایتها هشدار داد که فایلهای CSS و JS را مسدود نکنند و اجازه دهند که خزندههایش آنها را ببینند و لیست کنند.
با مسدود کردن فایلهای CSS و جاوا اسکریپت، از بررسی درست کارکرد وبسایت شما توسط گوگل جلوگیری میکنید. اگر فایلهای CSS و جاوا اسکریپت را در فایل yourrobots.txt مسدود کنید، گوگل نمیتواند سایتتان را آنطور که ساختهاید، ببیند و درک کند. با تکیه بر این مشکل، گوگل نمیتواند سایتتان را درک کند، ممکن است رتبه بسیار پایینی به آن بدهد.
علاوهبراین، حتی ابزارهایی مثل Ahrefs که صفحات وب را رندر میکنند و به کاربر نشان میدهند، با خواندن کدهای جاوا اسکریپت این کار را انجام میدهند. اگر دسترسی به فایلهای CSS و جاوا اسکریپت سایتها را در فایل robots.txt ببندید، ابزارهای سئو هم بهدرستی کار نمیکنند که در پی آن، نتیجه درست و دقیقی از بررسی سئو سایتتان توسط این ابزارها عایدتان نخواهد شد.
۳-تست فایل در سرچ کنسول گوگل و اینترنت
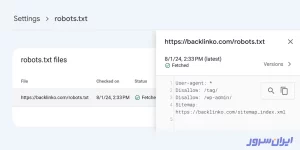
یکی از نکات مهم در بهینه سازی فایل robots.txt برای سئو، تست آن است که گوگل در این مورد به شما کمک میکند.
این کار بهشکل مستقیم از طریق بخش Settings سرچ کنسول انجام میشود که نمونهای از آن را در تصویر زیر میبینید:
برای مثال، در بخش پروفایل صفحه سرچ کنسول گزینه Blocked by robots.txt را انتخاب کنید تا صفحه زیر را ببینید:
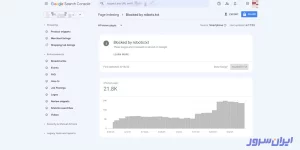
تمام مشکلات این صفحه را با دقت بخوانید و برطرف کنید. اگر در خواندن متنهای انگلیسی مشکل دارید، از هوش مصنوعی گوگل کمک بگیرید که Gemini نام دارد.
برای تست حضور این فایل روی سایتتان در اینترنت، میتوانید یک پنجره در مرورگرتان باز کنید و نام کامل دامنه را بههمراه robots.txt بنویسید. خط زیر این تست را نشان میدهد:
https://example.com/robots.txt
۴-استفاده از یک فایل robots.txt برای هر سایت
هر سایت و زیر دامنه آن باید فقط یک فایل robots.txt داشته باشد. در غیر این صورت، خزندهها گیج میشوند و فرصت خزش سایت شما بهطور کامل از دست میرود.
۵-متدهای افزایش امنیت فایل robots.txt
اگر میخواهید فایل robots.txt سایت یا زیر دامنهتان فقط از طریق یک پورت در دسترس باشد، آن را در مسیری مشابه مسیر زیر و در دایرکتوری root قرار دهید:
https://example.com:8181/robots txt
یک فایل robots.txt فقط برای مسیرهای درون یک پروتکل، هاست و پورتی که در آنها آپلود شده است، اعمال میشود. مثلا قوانین موجود در https://example.com/robots.txt، فقط برای فایلهای دامنه https://example.com/ اعمال میشود، نه برای زیردامنههایی مثل https://m.example.com/ یا پروتکلهای جایگزین، مانند http://example.com/.
۶-استفاده از خط جدید برای هر دستورالعمل
این روش را جزو برترین متدهای بهینه سازی فایل robots.txt برای سئو میدانیم که باید برای هر دستورالعمل، از یک خط جدید استفاده کنید. در غیر این صورت، موتورهای جستوجو نمیتوانند فرمانها را بخوانند و دستورات این فایل را نادیده میگیرند.
مثلا محتوای زیر در این فایل، شیوه نادرستی است:
User-agent: * Disallow: /admin/ Disallow: /directory/
اما در این نمونه، ما دستورالعملها را بهشکل درست و خوانایی نوشتیم:
User-agent: *
Disallow: /admin/
Disallow: /directory/
۷-استفاده یکباره از هر user-agent
از هر User-Agent فقط یکبار استفاده کنید تا همه دستورات مرتب و ساده باشند. علاوهبراین، احتمال خطای انسانی کاهش مییابد. این را بدانید که برای خزندهها اصلا مهم نیست چند بار از یک user-agent استفاده میکنید. در هر صورت آنها به user-agent خودشان دقت میکنند و بهمحض رسیدن به user-agent موتور جستوجوی دیگر، کارشان را به اتمام میرسانند.
پس این دستور اشتباه است:
User-agent: Googlebot Disallow: /example-page User-agent: Googlebot Disallow: /example-page-2
اما این دستورات کاملا درست، ساده و تمیز هستند:
User-agent: Googlebot Disallow: /example-page Disallow: /example-page-2
استفاده از یک کاراکتر Wildcard
کاراکترهای Wildcard در سئو، به کاراکترهایی اشاره دارند که گروهی از دایرکتوری یا پوشهها را هدف قرار میدهند و از تکرار چندباره یک دستور واحد جلوگیری میکنند. مثلا کاراکترهای * و ؟، یک Wildcard محسوب میشود که با استفاده از آن، یک دستورالعمل را برای همه user-agent و الگوهای URL بهکار میبریم.
مثال زیر، دو حالت اشتباه و درست را نشان میدهد. در این مثال، ما از دسترسی موتورهای جستوجو به URLهای دارای مقدار shoes جلوگیری کردیم.
این دستورالعمل شیوه نادرست استفاده از Wildcard در فایل robots.txt است:
User-agent: * Disallow: /shoes/vans? Disallow: /shoes/nike? Disallow: /shoes/adidas?
اما این محتوا، روش درست با استفاده از کاراکتر * و ؟ است:
User-agent: * Disallow: /shoes/*?
۸-توضیح دستورات بدون اجرای آنها
وقتی سایت بزرگ با میلیونها محتوا و هزاران صفحه دارید، برای فایل robots.txt توضیح بنویسید. با کاراکتر #، یک خط را کامنت کنید. این خط توسط هیچ موتور جستوجو و خزندهای خوانده نمیشود. بنابراین بار ترافیکی و پردازشی به سرورتان تحمیل نخواهد شد.
User-agent: * #Landing Pages Disallow: /landing/ Disallow: /lp/ #Files Disallow: /files/ Disallow: /private-files/ #Websites Allow: /website/* Disallow: /website/search/*
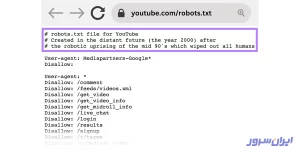
نایکی با همین کامنت گذاشتن خلاقیت بهخرج داده که در شکل زیر میبینید:

آنچه در فایل robots.txt خواندیم
فایل robots.txt یک فایل متنی ساده است که رفتار رباتها را مشخص میکند. زمانی که رباتهای موتورهای جستوجو به سایت ما سر میزنند، با خواندن این فایل متوجه میشوند که کدام صفحات را باید پیمایش و بررسی کنند و حق دسترسی به چه صفحاتی را ندارند. اگر از این فایل استفاده نکنیم، بار پردازشی و کاری سرورمان را بیشازحد زیاد میکنیم که بهضرر کسبوکارمان تمام خواهد شد.
ما تلاش کردیم در این آموزش، بهشکل کامل و جامع، موضوع فایل robots.txt چیست و چه اهمیتی برای سئو دارد را توضیح دهیم و تمام ریزهکاریهای آن را توصیف کنیم. اگر سوالی بیجواب مانده یا نیاز به توضیحات بخش خاصی دارید، حتما آن را در بخش نظرات بنویسید تا کارشناسان واحد فنی، پاسختان را بدهند.
سوالات متداولی که شما میپرسید
۱. فایل robots.txt چیست؟
یک فایل متنی که حاوی یکسری دستورالعملهای ساده است و رفتار رباتهای موتورهای جستوجو را مشخص میکند.
۲. چگونه فایل robots.txt سایتمان را پیدا کنیم؟
نام کامل سایتتان را در نوار جستوجوی مرورگر بنویسید، یک / بعد از آن بزنید و robots.txt را بنویسید و دکمه Enter کیبورد را بفشارید.
۳. دستور Disallow در فایل robots.txt چه کاری انجام میدهد؟
این دستور، دسترسی خزندههای موتورهای جستوجو را مسدود میکند.
منابع: